DynamoDB 데이터를 AWS 데이터 파이프라인으로 QuickSight에서 시각화하기
DynamoDB는 AWS에서 제공하는 NoSQL 데이터베이스로, 짧은 대기 시간과 고가용성을 제공하여 원활한 확장이 필요한 애플리케이션에 최적의 선택입니다.
AWS는 DynamoDB를 통해 증가하는 워크로드를 손쉽게 처리할 수 있도록 다양한 기능을 제공합니다.
Athena는 AWS 생태계 내에서 강력한 데이터 분석 도구로, 사용자가 익숙한 SQL을 사용하여 다양한 데이터 소스를 쿼리 할 수 있게 해 줍니다.
BI 작업이나 기타 분석 작업을 수행할 때, Athena는 프로세스를 단순화하고 데이터에서 인사이트를 도출할 수 있는 기능을 제공합니다.
이제 DynamoDB의 정보를 시각화해야 하는 요구가 생겼습니다.
아래와 같은 흐름을 통해, DynamoDB에 있는 데이터를 Athena로 옮기고 S3에 저장한 후, QuickSight로 시각화할 수 있습니다.

DynamoDB와 Athena를 연결해 주는 Connector Lambda는 AWS에서 제공해 주는 CloudFormation으로 생성 가능합니다.

데이터 원본을 DynamoDB로 선택하면 Cloudformation으로 DynamoDB와 Athena를 연결시켜 주는 Lambda Application를 생성할 수 있습니다.
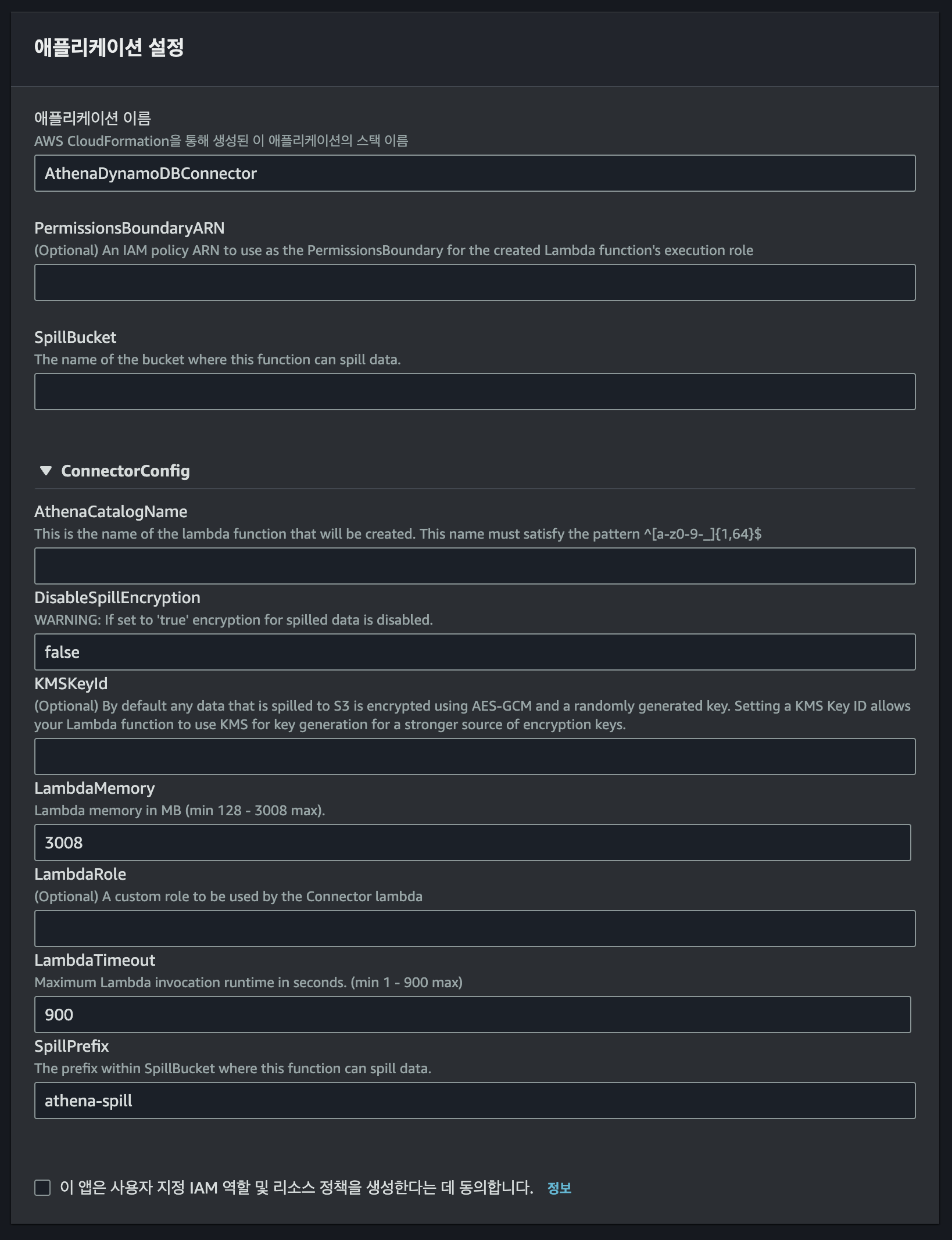
데이터를 저장할 버킷과 프리픽스(Prefix) 등은 Lambda 환경 변수로 커스텀할 수 있습니다.
- AthenaCatalogName: Lambda 함수의 이름입니다.
- SpillBucket: Lambda 함수 응답 크기 제한을 초과하는 데이터를 저장할 S3 버킷입니다.
- SpillPrefix: Lambda 함수 응답 크기 제한을 초과하는 데이터는 이 프리픽스(Prefix) 아래에 저장됩니다.
Amazon Athena DynamoDB 커넥터 - Amazon Athena
AWS Glue 콘솔의 테이블 작성 프로세스의 일부인 테이블 속성 설정 페이지에는 분류 필드가 있는 데이터 형식 섹션이 있습니다. 여기서는 dynamodb를 입력하거나 선택할 수 없습니다. 대신, 테이블을
docs.aws.amazon.com
하지만 Lambda를 사용할 때 "Column not found" 에러로 인해 샘플 컬럼만 가져오고 전체 컬럼을 가져오지 못하는 문제가 발생할 수 있습니다.
🔥 How can I resolve the "Column not found" error with the Athena DynamoDB connector?
Troubleshoot "Column not found" error in Athena DynamoDB connector
When I use the Amazon Athena DynamoDB connector, I get a "Column not found" error.
repost.aws
이를 해결하기 위해 AWS Glue Crawler를 사용하여 DynamoDB와 Athena를 연결해 줍니다.
AWS Glue는 완전 관리형 데이터 추출, 변환 및 적재(ETL) 서비스입니다.
서버리스이기 때문에 설정하거나 관리할 인프라가 없으며, 원본 데이터의 변경을 감지하여 저장할 별도의 저장소가 필요 없습니다.
원하는 데이터 원본과 Glue가 해당 데이터 원본에 접근할 수 있도록 IAM Role을 연결해 줍니다.


크롤러가 데이터 원본의 스키마 변경을 감지하면, AWS Glue는 Data Catalog의 테이블을 자동으로 업데이트합니다.
또한, 데이터 원본에서 삭제된 객체에 대해 어떻게 처리할지 설정할 수 있는 다양한 옵션을 제공합니다.
크롤러 스케줄러는 필요에 따라 on-demand로 실행하거나, cron 기반으로 일정에 맞춰 자동 실행되도록 설정할 수 있습니다.


처음에는 Lambda를 사용하여 DynamoDB와 Athena를 연결하려 했지만, "Column not found" 에러로 인해 전체 컬럼을 가져오지 못하는 문제가 발생했습니다.
이 문제를 해결하기 위해 AWS Glue Crawler를 도입하여 DynamoDB와 Athena를 연결하여 데이터를 시각화할 수 있었습니다.
AWS Glue는 완전 관리형 서버리스 ETL 서비스로, 데이터 원본의 스키마 변경을 자동으로 감지하고 Data Catalog를 업데이트해 주어 더 안정적이고 효율적인 데이터 파이프라인을 구축할 수 있었습니다.
또한, 크롤러 스케줄러를 활용하여 데이터 업데이트를 자동화함으로써 관리 부담을 줄일 수 있었습니다.
이 과정을 통해 DynamoDB 데이터를 Athena와 QuickSight로 시각화하는 파이프라인을 성공적으로 구축할 수 있었습니다.
이 방법은 비슷한 데이터 시각화 요구 사항이 있는 경우에 유용하게 사용할 수 있습니다.
